
Backgroud
在先前我們在介紹 Transformer的架構時,都知道該架構所涵蓋的參數量非常大,必須耗用的資源也非常之多,即便他替NLP這個領域開創了一個契機,但反之也有許多可改善的空間。所以今天要來探討的這篇paper,就是要解決一些Transformer的痛點,是Google在2020年年初提出的架構 - Reformer,相關paper連結如下:
REFORMER: THE EFFICIENT TRANSFORMER
關於Transformer的問題,我們可以先簡單列舉如下:
Transformer架構無法採用long-sequence,最多只能採用 512的token來作為句子訓練,並且batch_size依據實驗也不適合過大。Transformer在Self-Attention的機制當中,是每一個Query要與其他token的Key去做Dot-Product,因此會造成時間複雜度 O(N^2),即便句子很短也需要這麼多的時間。- 在
Transformer的Encoder架構當中有一個sublayer-FFN,其內部的hidden-size比input, output size來得大,這會造成許多GPU記憶體的浪費。 Transformer會存每一個layer activation後的結果,會造成記憶體用量N被成長。
然而,Reformer為了解決這些痛點提出了幾個解決方針,且促使整體的時間複雜度從O(N^2)降到O(NlogN),其中提出的方法列舉如下:
1. Locality Sensitive Hashing(LSH) Attention
2. Reversible layers
3. Chunking FFN layers
透過這些方法,Reformer除了可以訓練達64K長度的句子之外,同時也提升資源使用與訓練的速度,所以接下來要針對這些方法去做討論。
Locality Sensitive Hashing(LSH) Attention
如果大家還記得原先Transformer在計算Sefl-Attention,它採用的公式如下:
\begin{equation}
Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
\end{equation}
上面這是在計算attention-score的公式,在原先Transformer的架構中,當輸入的句子進來會經過embedding來得出不同的embedding-Q,K,V,再來才會計算Attention。
但是這點在作者的眼裡認為這會造成不必要的參數浪費,因為作者這邊提出了一個方法,就是Shard-QK Transformer,簡單來說就是直接使 Q=K,來減少參數量,且在實驗結果中並沒有減少Model的Performance。
接下來來說明一下何謂Locality Sensitive Hashing(LSH)? 我們先來回頭看一下剛剛的公式:
這邊我們可以看到在原先 Transformer架構中有一個\sqrt{ d_k }的計算,因為Q會與每一個token所對應的K去做計算,但有些可能經過softmax之後可能會趨近於0(代表沒什麼關係),對於Model來說事實上只有softmax後value較大才比較有影響,所以作者在這邊就決定將不相關的K做忽略,甚至只保留有相關的 Top32 或 64的K。其中就是透過Locality Sensitive Hashing(LSH)去做到這件事情。
這邊有提到一個關鍵字- Hash,如果對於資料結構不陌生的話,Hash簡單來說就是要讓value透過Hash Function來歸類到不同的Bucket,經過Hash Function後的輸出如果是一樣的話,就代表原先輸入的Value會被歸類為一類。舉例來說,如下:
7 mod 3 = 2
4 mod 3 = 1
2 mod 3 = 2
假設 Hash Function是mod,那麼7,2就會被歸類在同一類(因為Hash值相同)。此外,透過Hash的作法,可以有效讓時間複雜度降到O(N),因為只要經過一次查訊就可以找到對應的值。
但一般來說,正常的Hash是沒有考慮距離問題的,怎麼說呢,從剛剛的例子可以看到7,2距離較遠但卻被歸類到同一個Bucket當中。但對於句子文字來說,作者想要保證距離較遠(不相關)的K(拿K做Hash)能被歸類到不同的Bucket,較相關的可以被歸類同樣的Bucket,而LSH就可以做到這個效果。大致的結果呈現下圖:
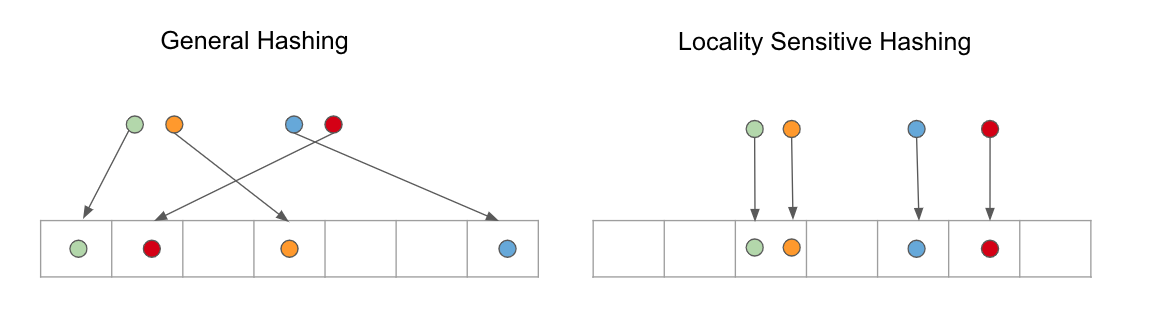
如此一來就可以促使距離較近的K可以被歸類到同一個Bucket,距離較遠的就可以被分類到同一個Bucket的機率也較低。
作者這邊也有畫出一個簡單的示意圖,如下:
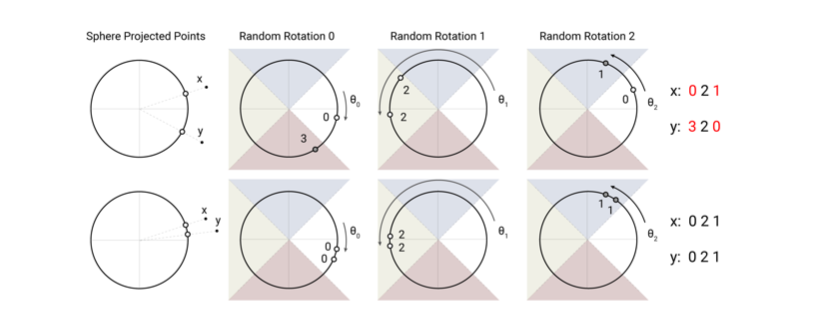
在上部分,x和y距離較遠,所以在三次隨意旋轉後,有兩次投影都不一樣;而在示意圖的下部分,x和y距離較近,在三次的隨意旋轉後,三次都投影都一樣,這就是LSH的概念。
接下來說明一下,該如何將LSH整合到Attention裡面,可以先看如下公式:
\begin{equation}
oi = \sum{j \in{P_i}} exp(q_i \cdot k_j-z(i, P_i))v_j
\end{equation}
對於Decoder來說,每個token的Query 𝑞𝑖 只能參照到自己與先前的token之key 𝑘𝑗,𝑃𝑖是指Position i 可以參考的position,然而對於無法參照的position(attention-score為0),就會以$\infty$做表示,代表不需要考慮這個position的token,如此一來就可以不用考量全部的token。也就是說,只要考慮𝑃𝑖內的keys,公式即
\begin{equation}
P_i = j: h(q_i) = h(k_l)
\end{equation}
或許這樣說明還不夠清楚,作者在論文當中提供了一張流程圖來讓我們一步一步釐清當中的作法,流程圖如下:
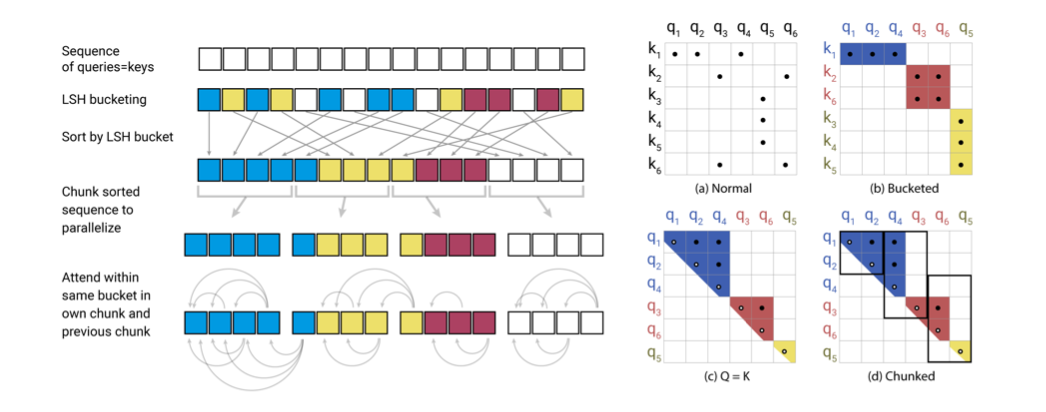
我們先看右半邊的圖,詳細地步驟如下:
- 圖(a)這邊可以看到這是 Encoder的Attention,因為正常情況下$q_3$是無法關注到$k_6$,這邊可以看到對於要關注的位置是稀疏
- 圖(b)接著透過 LSH來關注到相同 Bucket內的 keys,並且按照Bucket來做排序,因此會得到圖(b)。我們可以發現一個Bucket中會有多的Query但很少Key的情況。
- 所以這時候做Shard-QK Attention,也就是將Q=k,來解決Q,K不均衡的問題。而圖(C)也可以看到有『空心』的符號,因為在
Shard-QK Attention如果關注自己本身會造成其他的attention score很低,因此必須加以排除。 - 圖(d)最後,即便Q=K,會出現有個Bucket個數很多,有些Bucket個數很少,然而也會有Bucket佔據了一些Keys,為了讓LSH有效果,作者在這邊加入了Chunk機制,會先設定每個Bucket的大小 $m=\frac{2l}{n_{bucket}}\qquad$,($l$為query的個數),對於每一個Bucket來說可以關注自己當前與前一個Bucket中相同Hash的Key因此 $\tilde{P_i}$ 轉換如下:
\begin{equation}
oi = \sum_{j \in{P_i}} exp(q_i \cdot k_j-z(i, P_i))v_j
\end{equation}
這邊總結一下整體過程,即可參考左半邊的順序圖:
1. 先設定Q=K
2. 執行 LSH Bucket,來歸類到每一個Bucket中
3. 依據bucket來做排序
4. 進行Chunk的拆分
5. 最後每一個Bucket的Query可以關注當前與前一個bucket相同的Key
Multi-round LSH attention
讀者透過上一節想必對於LSH有些基本的認識了,作者在這邊除了做一般的LSH,也延伸使用了Multi-round LSH attention,這邊簡單來說,依據作者在論文的流程,我們能看到一個狀況,就是有些可能是相同的key但卻被分到不相同的Bucket中,也就是『不能保證相關的輸入能被分類到相同的Bucket』,所以為了降低這樣的機率,採用的Multi-round,重複該過程多次,以使相關的 item 儘可能高的機率落入相同的Bucket中,儘量避免相似 item 落入不同Bucket,對應的公式如下:

Reverible Transformer
在Transformer當中的sublayer,每次的attention會與FFN做連結,就必須記憶每一個layer的activation,這會造成記憶體浪費,這裡作者引用了RevNet的作法,不保留中間層的activation,之記住最後一層的activation,接著透過推導來求得每一層的輸入。
還記得Transformer運用了Residual connection,其中的輸出是 $y=x+F(x)$。但在 RevNet當中是如何做到Reverible,首先一開始是將輸入$x$分成$x_1$, $x_2$,並且透過不同的 Residual functions $F()$, $G()$來得到輸出的 $y_1$, $y_2$,簡單的正向傳遞圖示如下:
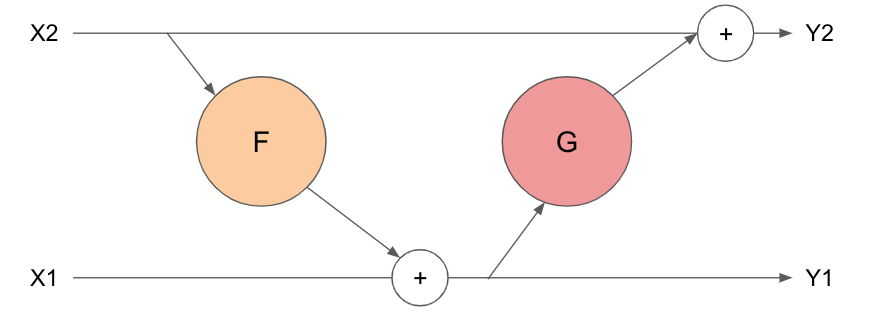
公式如下:
\begin{equation}
y_1 = x_1 + F(x_2)\
y_2 = x_2 + G(y_1)
\end{equation}
Reverible的倒傳遞圖如下:
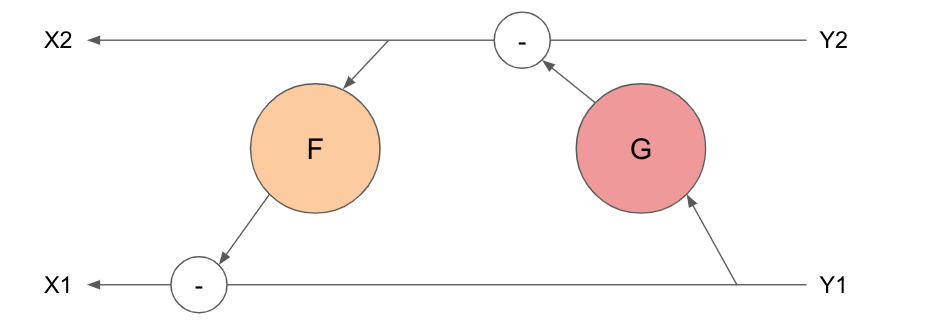
公式如下:
\begin{equation}
x_2 = y_2 - G(y_1)\
x_1 = y_1 - F(x_2)
\end{equation}
- 可以看到計算 $x_2$時只運用了上一層的 activation值 $y_1$, $y_2$,而計算$x_1$則是運用前一步進算出來的$x_1$,因此不需要儲存額外的activation(時間換空間)
- 透過這樣節省記憶體空間,
Reformer可計算更長的sequence。
這邊套用到Transformer,attention layer為F function; FFN layer為G function,利用這個方式就可以避免儲存中間過多不必要的activation。
\begin{equation}
y_1 = x_1 + Attention(x_2)
y_2 = x_2 + FFN(y_1)
\end{equation}
Chunking
在原先Transformer當中,FNN的中間hidden-size 維度其實非常大,作者為了降低memory的使用,透過Chunk來拆分計算,每次計算一個Chunk,也是一種時間換空間的方式。
\begin{equation}
Y_2 = [Y_2^{(1)}; ...; Y_2^{(c)}] = [X_2^{(1)} + FeedForward(Y_1^{(1)});...;X_2^{(c)} + FeedForward(Y_1^{(c)})]
\end{equation}
Experiments
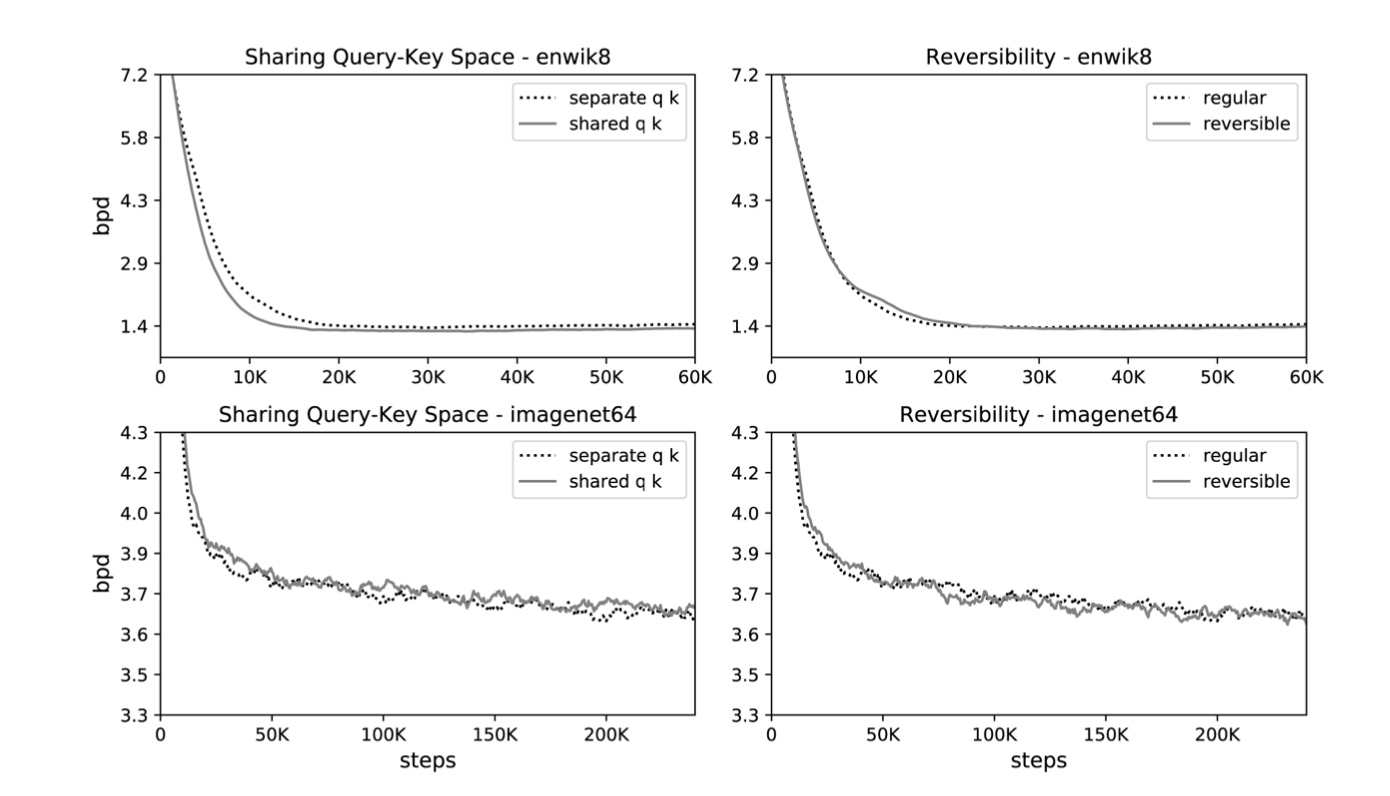
上圖左半部是Shared-QK的作法,我們可以發現無論是enwiki8或imagenet64這兩種資料集,並不會比一般的attention做法來得差; 右半部則是使用Reversible的方式,可以看到該方法即便節省了非常多記憶體與參數,但相比Transformer也不會降低精準度。
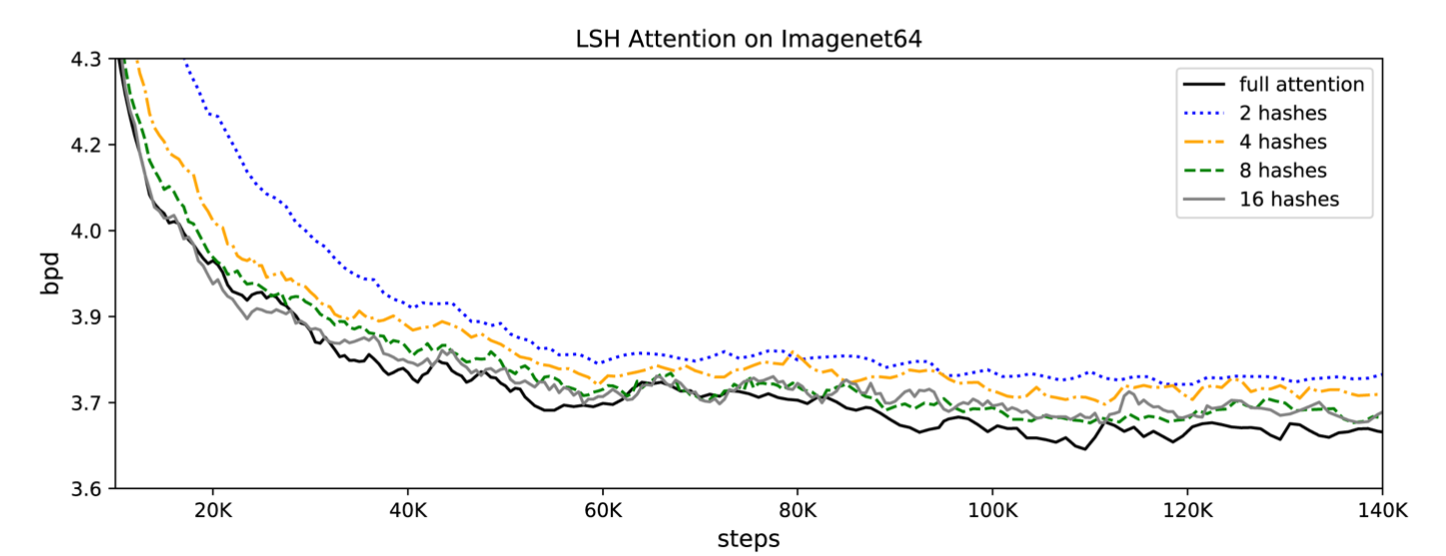
這邊作者也發現當Hash數增加時,也同時增加了精準度,因為分發的Bucket越多了,也更有空間讓相近的Key被存放同一個Bucket。
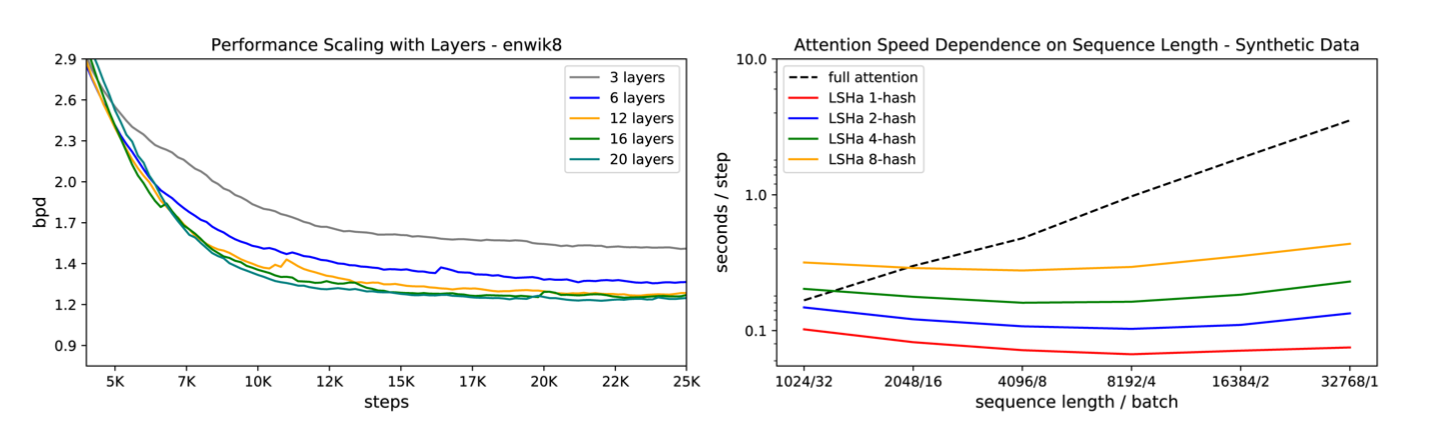
這裡呈現了不同layer數的Reformer的表現,左邊我們可以發現當Layer數增加時,整體訓練的效益仍是存在的,右圖可以發現一般Attnetion和LSH Attention在不同Sequence Length的速度比較,當Sequence Length很長時,LSH Attention帶來的效果相較更加出色。
Conclusion
Reformer除了延伸了Transformer的精神之外,也改善了一些缺點,包含使用較少的記憶體訓練與計算、可訓練較長的Sequece、也可以在單機做訓練等,有了這些改進,就可以對於較長的句子、文本可以作更好的訓練效果,也可以應用到其他的領域來做長sequence訓練且提升訓練速度與效益。


![[Java_note]多載(Overload), 覆寫(Override), 多型(Polymorphism)](https://tzutzu.coderbridge.io/2020/07/24/Overload-Override-Polymorphism/?utm_source=coderbridge-io&utm_medium=blog_related_post_img&utm_campaign=AI Tech & Paper Space_[Java_note]多載(Overload), 覆寫(Override), 多型(Polymorphism)_@tzutzu858_https://static.coderbridge.com/images/covers/default-post-cover-2.jpg)


